βフェーズが続いていたCircleCI 2.0ですが、先日めでたくリリースされました。おめでとうございます🎉

というわけでここからは何回かに分けてCircleCI2.0の使い方や活用法を解説していこうと思う💪
変わったところ
2.0はほぼReスクラッチで諸々一新されている。3月に開催されたCircleCI Meetup #2に来られた方なら知ってると思われるが、バックエンドの仕組みも相当変わったらしい。
機能的なところでトピックを挙げると、
- circle.yml記法の一新
- 高速化
- ローカルビルドサポート
- 独自のビルドイメージの作成
- Native Dockerサポート
- workflowsの登場(ビルドパイプラインみたいなもの)
といったところが代表的に挙げられる。
今回のエントリではCircleCI2.0におけるcircle.ymlの新しい記法と基本的な使い方、2.0の目玉機能の一つであるworkflowsを紹介したい。
CIで実現したいこと
このブログはHugoを使って書かれていてGitHubにリポジトリとして置いてあり、CircleCIでCIを回して更新している。
やっていることは
- 依存するツールのインストール(HugoとPygments)
- ブログをHugoでビルド
masterにマージされた場合、awscliを使いAmazon S3に成果物を転送する
といった感じ。これを実現するためのCircleCI 1.0時代のcircle.ymlが以下のようなもの。
dependencies:
pre:
- go get -v github.com/gohugoio/hugo
- pip install Pygments
override:
- hugo -t casper:
pwd: blog
test:
override:
- echo noops
deployment:
master:
branch: master
owner: stormcat24
commands:
- aws s3 sync blog/public s3://ブログのs3バケットだよ/
これをCircleCI 2.0に置き換えていく。
新しいcircle.yml
まずは基本的なスニペットを貼ろう。
version: 2
jobs:
build:
working_directory: ~/blog.stormcat.io
machine: true
steps:
- checkout
- run:
name: install hugo
command: go get -v github.com/gohugoio/hugo
- run:
name: install pygments
command: pip install pygments
- run:
name: build hugo
pwd: blog/
command: hugo -t casper
2.0を利用することを宣言するために、新たにversion要素が追加された。version: 2を記述すると2.0でビルドが開始される。
次にトップレベル要素としてjobsがある。jobsはジョブを複数定義できるもので1つにつきCIが1つ実行されると考えて良い。子要素としてbuildを定義しているが命名は一意になればなんでも良い。
working_directoryではVM上におけるCIの実行ディレクトリを指定することができる。~/blog.stormcat.ioとしているが、フルパスだと/home/circleci/blog.stormcat.ioとなる。このディレクトリを起点に全ての処理が行われる。
machine: true を設定するとVMでCIを実行することになる。2.0ではDockerコンテナ内でのビルドをすることが可能になったが、Dockerに馴染みが無いとわかりにくいと思うのでオーソドックスにデフォルトのVMを利用する。
stepsはビルドステップのことで、CIで実行していきたい処理をシーケンシャルに羅列していけばいい。checkoutはCircleCIで用意されているビルドステップのエイリアスみたいなもので、対象のリポジトリをVM上にチェックアウトする命令。チェックアウト後のステップは実現したいことを記述いけばよい。この例では、Hugoを使ってブログをビルドするまでを書いている。
workflowsを定義する
これだけだと1.0を2.0で動かせるようにしたにすぎないので、2.0の目玉であるworkflowsを使ってビルドを分けてみよう。
version: 2
jobs:
build:
working_directory: ~/blog.stormcat.io
machine: true
steps:
- checkout
- run:
name: install hugo
command: go get -v github.com/gohugoio/hugo
- run:
name: install pygments
command: pip install pygments
- run:
name: build hugo
pwd: blog/
command: hugo -t casper
- save_cache:
key: blog-{{ epoch }}
paths:
- ~/blog.stormcat.io/blog
deploy:
working_directory: ~/blog.stormcat.io/blog
machine: true
steps:
- restore_cache:
keys:
- blog
- run:
name: deploy hugo
command: aws s3 sync public s3://ブログのs3バケットだよ/
workflows:
version: 2
build_and_deploy:
jobs:
- build
- deploy:
requires:
- build
filters:
branches:
only: master
新たにdeployというジョブを追加している。1.0ではジョブを分けるという概念がなかったため、何らかの外部要因によりデプロイが失敗した場合、CIは最初からやり直す必要があった。デプロイだけをやり直したいケースにおいては時間の無駄となる。
2.0ではworkflowsを定義することでジョブを分割して実行できることが可能になった。workflowsを利用するためにジョブを分けて定義している。
buildジョブにおいて、新たにsave_cacheを追加した。ここではブログをビルドしてできあがった成果物があるパスをキャッシュとして保存している。workflowsによって、deployジョブはbuildジョブとは別に起動するため、その成果物を次のジョブに渡す必要が生じるからためであり、その方法としてsave_cacheを使う。
キャッシュはkeyを設定して名前をつけることができる。ここでは-{{ epoch }}というプレースホルダがついているが、こうすることで毎回のビルドでキャッシュを分離するということが可能になる(1.0時代はキャッシュでハマることがあったのでこれはありがたい)。
保存したキャッシュはdeployジョブにおいてrestore_cacheにてkeyを指定して取り出している。ここではepoch未指定だが、こうした場合は直近のキャッシュが取り出され成果物を引き継ぐことができる。
ここまでくればあとはs3にデプロイする処理を入れるだけとなる。
workflowsの設定は基本的にジョブを順番に記述していくだけだが、requiresで依存ビルドだったり、filters.branchesによって実行するブランチを制限したりすることができる。deployではmasterブランチだけでの実行に制限しているので、PullRequestベースで開発してmasterにマージされたときだけデプロイするような処理の場合にこの手法は使える。
approvalでジョブを承認する
workflows機能の良いところとしてapprovalという機能がある。これは何かというと、masterにマージされると自動的に実行される処理を、ワンクッション置いてApproveボタンで人が承認して初めて実行されるというものだ。怖いオペレーションが実行するようなケースでは有用な手法。これをcircle.ymlに組み込んでみよう。
version: 2
jobs:
build:
working_directory: ~/blog.stormcat.io
machine: true
steps:
- checkout
- run:
name: install hugo
command: go get -v github.com/gohugoio/hugo
- run:
name: install pygments
command: pip install pygments
- run:
name: build hugo
pwd: blog/
command: hugo -t casper
- save_cache:
key: blog-{{ epoch }}
paths:
- ~/blog.stormcat.io/blog
approve:
working_directory: ~/blog.stormcat.io
machine: true
steps:
- run:
name: noope
command: echo noope
deploy:
working_directory: ~/blog.stormcat.io/blog
machine: true
steps:
- restore_cache:
keys:
- blog
- run:
name: deploy hugo
command: aws s3 sync public s3://ブログのs3バケットだよ/
workflows:
version: 2
build_and_deploy:
jobs:
- build
- approve:
type: approval
requires:
- build
filters:
branches:
only: master
- deploy:
requires:
- approve
filters:
branches:
only: master
新たにapproveというechoしてるだけのジョブを追加した。重要なのはworkflowsの設定の方で、approveジョブにtype: approvalを設定してある。さらにdeployジョブをapproveジョブに依存させる。こうすることで、以下のようにworkflowsのUIに**Approve(承認)**のボタンが現れる。
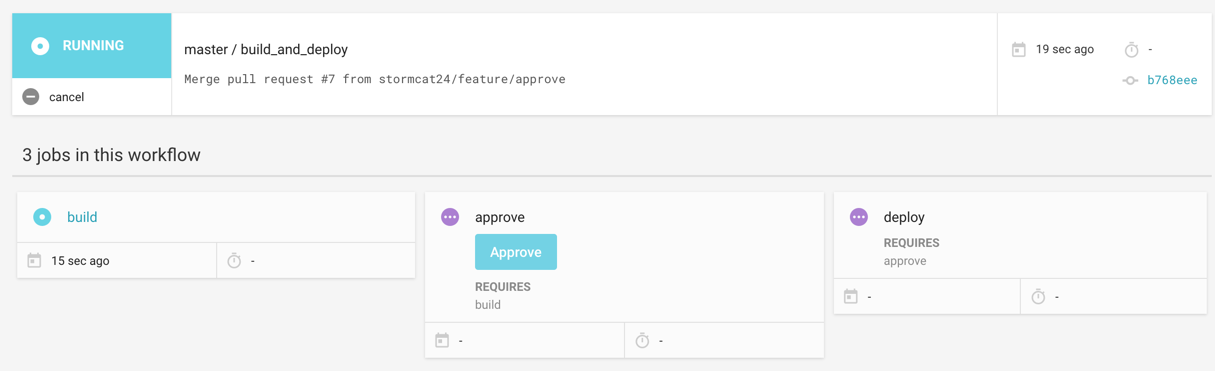
masterブランチにおいてCIが実行されると、まずbuildジョブが実行されるが、approveジョブ差し掛かるとON HOLDとなってCIが止まる。
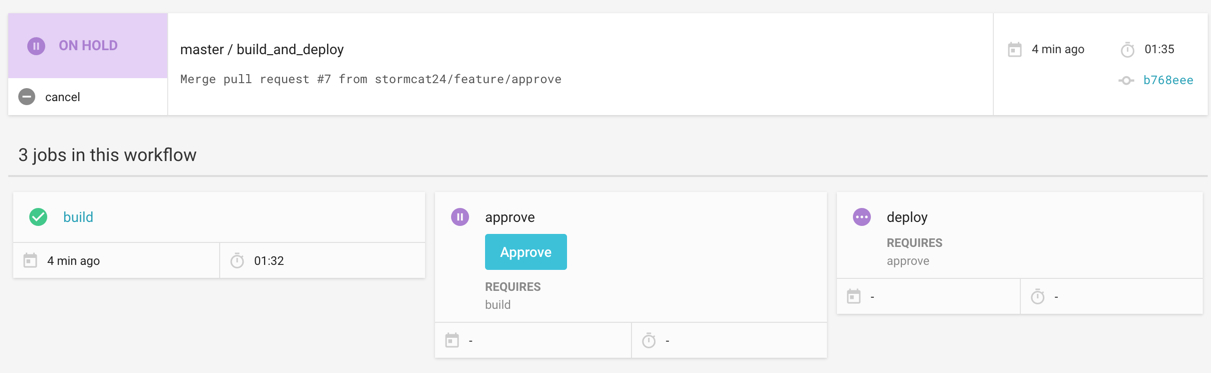
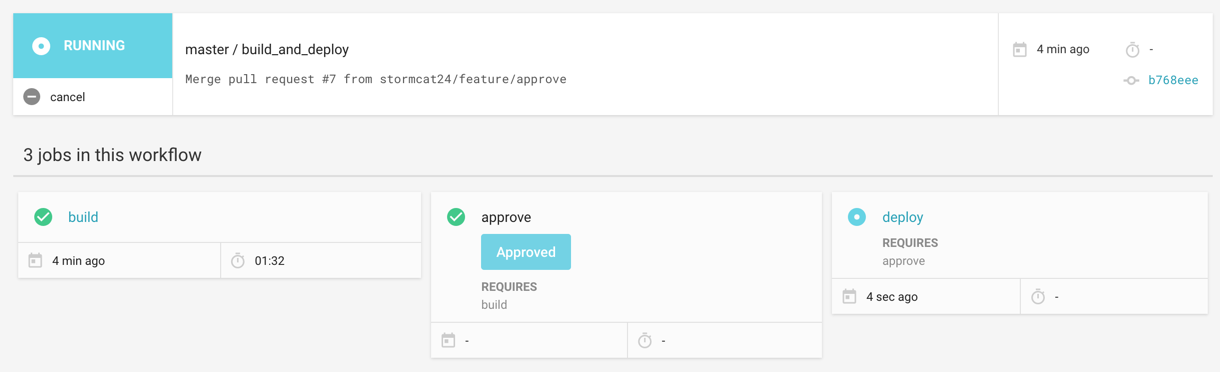
この状態においてApproveを押すと、止まっていたジョブが再開しdeployジョブが実行される。masterのビルド結果を確認してからオペレーションを実行したい場合もあるので、1.0時代より精神的余裕が生まれると感じている。
さあ、始めよう。
何となくCircleCI2.0の活用イメージは掴めたかと思う。CircleCIユーザーも、そうでない人も是非試してみて欲しい。このシリーズはまだまだ続ける予定なので、次回以降はさらに実践的な使い方を紹介するつもり。